In this guide, we will show you how to increase data throughput for LLMs using batching, specifically by utilizing the vLLM library. We will explain some of the techniques it leverages and show why they are useful. We will be looking at the PagedAttention algorithm in particular. Our setup will achieve impressive performance results and is well suited if you need to process a significant amount of data. We will also perform some tests to determine to what extent vLLM speeds up inference times. Firstly by comparing vLLM batching to non-batching performance and secondly, by comparing the speed of vLLM to Hugging Face’s Transformers library. We will be performing this demonstration with UbiOps.
What is UbiOps?
UbiOps is a model serving and management platform with state-of-the-art deployment hardware, logging and performance metrics, fine-tuning options, and workflow-optimization tools such as pipelines. You can read more about what a model-serving platform is by reading this article.
Essentially, UbiOps allows you to easily deploy and manage your models. We also offer a free trial. Learn which LLM is best for you here, or if you are interested in fine-tuning, read this article about creating your own chatbot which has been fine-tuned on your own documentation.
What is vLLM?
vLLM is a python library developed by Berkeley in 2023 which helps you create optimized ML workloads. It is built to deal with high-throughput and memory-constrained workloads. It uses a state-of-the-art algorithm named PagedAttention which efficiently manages attention-level key-value pairs. It is well suited for batch requests and can process them at high speeds. According to their docs, vLLM’s main advantages are:
-
- State-of-the-art serving throughput
-
- Efficient management of attention key and value memory with PagedAttention
-
- Continuous batching of incoming requests (not currently supported with UbiOps)
-
- Fast model execution with CUDA/HIP graph
-
- Quantization
-
- Optimized CUDA kernels
vLLM is far more performant than Hugging Face’s Transformers. We will show this by performing some benchmarks at the end of the article.
What is PagedAttention?
PagedAttention is an algorithm delineated in the academic paper Efficient Memory Management for Large Language Model Serving with PagedAttention. It solves the long-standing problem of request batching:
-
- The memory required for key-value caching is too dynamic
-
- It can be stored inefficiently
-
- It can have redundancy issues
PagedAttention essentially uses paging techniques—a method of mapping hardware addresses to virtual addresses—to solve these issues and in the process creates a much more memory-efficient architecture. It divides a request’s key-value cache into blocks, which contain the attention key-value pairs of a fixed amount of tokens. Attention-level key-value pairs are tokens which are used as inputs in Transformers. This eliminates internal fragmentation, an issue where assigned memory is underused. This is how PagedAttention allows for very memory-efficient computations.
vLLM utilizes this technique, making it orders of magnitudes more efficient than the Hugging Face Transformers library. We will demonstrate this by performing comparison tests at the end of this article. In our past guides, we utilized Hugging Face’s Transformers library. Now, we will show you what you can do using vLLM.
What is Batching?
Batching is, in a general sense, a method of combining together multiple requests and processing them all at once. In GenAI, it is a technique that leverages the ability of accelerated hardware to perform parallel calculations to increase the overall throughput. As we will show in this guide, batching can optimize throughput by several times and lead to an overall better experience for the user of the LLM.
What is continuous batching?
According to vLLM’s documentation, they utilize a technique called continuous batching. This allows for the amount of requests in the current batch to grow and shrink dynamically as the model generates each token. Meaning that you can continuously send new requests and they will be processed inside the current batch.
This technique is very useful for high-load use cases when you are getting hundreds or thousands of inference requests a minute.
Most sites load under 5 seconds, and therefore speed is crucial when generating responses in your GenAI application. Some research shows that 40% of consumers will abandon a site if it takes longer than 3 seconds to load. Therefore, the time delay between a user’s request and response is around 3 seconds. Your GenAI application should consider this benchmark. With vLLM, results like that are not only achievable for single requests, but also for high-load use cases with batch requests.
vLLM batching on UbiOps
We will now explain how to construct a UbiOps Deployment and `deployment.py` file which utilizes the vLLM library. Let’s first take a look at the initialization. If you want the entire code, see the appendix. For the dependency requirements, see the Appendix. Make sure to select: “Ubuntu 22.04 + Python 3.10 + CUDA 12.3.2” as a base environment.
Firstly, we define the model: mistral-7b-instruct-v0.2, and retrieve its tokenizer from HuggingFace using the Transformers library. Note: Mistral models have recently become gated models, and you will need to accept their license agreement on the model page, and insert your token to authenticate yourself.
class Deployment:
def __init__(self, base_directory: str, context: Dict[str, Any]) -> None:
"""
Initialisation method for the deployment. Any code inside this method will execute when the
deployment starts up.
It can for example be used for loading modules that have to be stored in memory or setting
up connections.
"""
self.model_name = "mistralai/Mistral-7B-Instruct-v0.2"
hf_token = "<insert_your_hf_token_here>"
login(token=hf_token)
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)</insert_your_hf_token_here>
Next, we define the LLM object using vLLM’s library. We also define a base prompt and a system-level prompt.
class Deployment:
def __init__(...):
...
self.base_prompt = (
"<s>[INST]\n<<sys>>\n{system_prompt}\n<</sys>>\n\n{user_prompt}[/INST]"
)
self.llm = LLM(model=self.model_name, max_model_len=15152)
self.default_config: Dict[str, Union[bool, int, float]] = {}
self.system_prompt = "You are a friendly chatbot!"</s>
Batching
In your `deployment.py` file you will need to define both a “request()” and a “requests()” method. The “requests()” method gets called when the request contains a list of prompts. The “request()” method expects a dictionary white the “requests()” method expects a list of dictionaries.
We first retrieve the list of all prompts, formatting “self.base_prompt” based on the user prompt and the system prompt. This is the format which we need to use in order to pass it as a batch request to the LLM object.
class Deployment:
...
def requests(self, data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""
Method for deployment batched requests, called once for each batch request.
"""
full_prompts = [
self.base_prompt.format(
system_prompt=element['system_prompt'], user_prompt=element["prompt"]
) for element in data
]
Next, we call the “generate()” method. Passing all the prompts in the request and setting standard sampling parameters, we have made it so it only generates 16 tokens at maximum per response.
class Deployment:
...
def requests(...):
...
sampling_params = SamplingParams(**data[0]["config"]) if data else SamplingParams(max_tokens=16)
outputs = self.llm.generate(full_prompts, sampling_params)
Next, we create the output dictionary and return it.
class Deployment:
...
def requests(...):
...
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
processed_outputs.append({
'input': prompt,
'output': generated_text,
'used_config': data[0]["config"] if data else {}
})
return processed_outputs
Note, in this code we have defined 3 input and 3 output fields which should be created in the deployment as such:

And there we have it! Let’s checkout exactly how much it improved the speed.
Performance Comparison
We will now perform some tests to determine the difference in speed between batched and non-batched requests.
Batching vs. single requests for vLLM
Let’s see how much faster vLLM can process batch requests.. We will perform 100 requests in series as individual requests and then in parallel as one batch request. We are running both tests on the same hardware, an NVIDIA Ada Lovelace L4 GPU. The requests are also the same for each run and we will only generate 16 tokens per response. We ran each test three times. Here are the results:
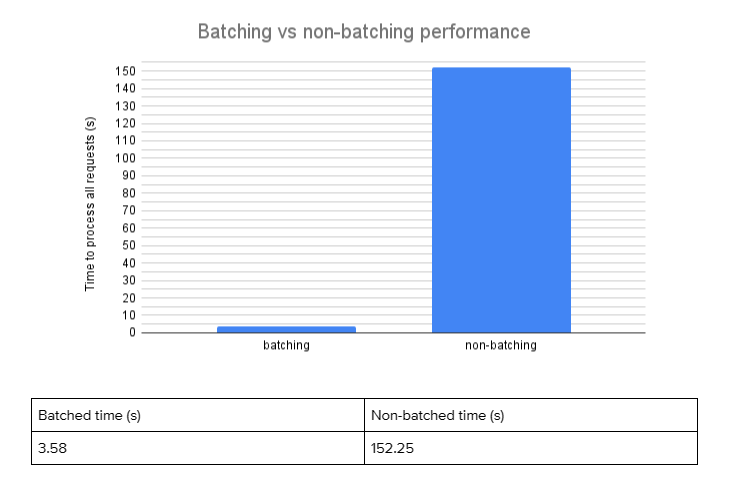
As we can see, using batching is around 43 times faster than processing each request individually, with batching techniques taking around 3.58 seconds to process 100 prompts and non-batching takes around 152.25 seconds. When running applications with a high load, batching is clearly a must have.
Conclusion
To summarize, we gave an overview of how to use vLLM, request batching, and UbiOps together. This setup can achieve an impressive throughput and is superior to a similar setup on the Transformers library—according to our test results. In general, this setup is perfectly suited for use cases where you are processing a significant amount of data or are receiving multiple inference requests a second.
If you are new to UbiOps, create an account here! We are an AI management platform with guides ranging from how to deploy gemma-2b for free to explaining the difference between open-source and closed-source models. Thanks for reading!
Appendix
deployment.py:
from typing import Any, Dict, List, Union
import os
from vllm import LLM, SamplingParams
from transformers import AutoModelForCausalLM, AutoTokenizer
from huggingface_hub import login
class Deployment:
def __init__(self, base_directory: str, context: Dict[str, Any]) -> None:
"""
Initialisation method for the deployment. Any code inside this method will execute when the deployment starts up.
It can for example be used for loading modules that have to be stored in memory or setting up connections.
"""
print("Initialising deployment")
self.model_name = os.environ.get("MODEL_ID", "mistralai/Mistral-7B-Instruct-v0.2")
hf_token = "<insert_your_hf_token_here>"
login(token=hf_token)
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
self.base_prompt = (
"<s>[INST]\n<<sys>>\n{system_prompt}\n<</sys>>\n\n{user_prompt}[/INST]"
)
self.llm = LLM(model=self.model_name, max_model_len=15152)
self.default_config: Dict[str, Union[bool, int, float]] = {}
self.system_prompt = "You are a friendly chatbot!"
def request(self, data: Dict[str, Any]) -> Dict[str, Any]:
"""
Method for deployment requests, called separately for each individual request.
"""
print("Not Batching")
system_prompt = data["system_prompt"] if "system_prompt" in data else self.system_prompt
config = self.default_config.copy()
if "config" in data:
config.update(data["config"])
full_prompt = self.base_prompt.format(
system_prompt=system_prompt, user_prompt=data["prompt"]
)
sampling_params = SamplingParams(**config)
sequences = self.llm.generate(full_prompt, sampling_params)
return {
"output": sequences[0].outputs[0].text,
"input": full_prompt,
"used_config": config
}
def requests(self, data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""
Method for deployment batched requests, called once for each batch request.
"""
full_prompts = [
self.base_prompt.format(
system_prompt=element['system_prompt'], user_prompt=element["prompt"]
) for element in data
]
sampling_params = SamplingParams(**data[0]["config"]) if data else SamplingParams(max_tokens=16)
outputs = self.llm.generate(full_prompts, sampling_params)
processed_outputs = []
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text # Assuming only one output is generated per prompt
processed_outputs.append({
'input': prompt,
'output': generated_text,
'used_config': data[0]["config"] if data else {}
})
return processed_outputs
</s></insert_your_hf_token_here>
requirements.txt:
vllm==0.3.0
transformers
ubiops.yaml:
apt:
packages:
- gcc
The post How to optimize inference speed using batching, vLLM, and UbiOps appeared first on UbiOps - AI model serving, orchestration & training.